
[TOC]
Arraylist
集合是Java中提供的一种容器,可以用来存储多个数据。底层采用的数组结构
ArrayList al=new ArrayList();//创建了一个长度为0的Object类型数组
al.add("abc");
//底层会创建一个长度为10的Object数组 Object[] obj=new Object[10]
//obj[0]="abc"
//如果添加的元素的超过10个,底层会开辟一个1.5*10的长度的新数组
//把原数组中的元素拷贝到新数组,再把最后一个元素添加到新数组中
集合和数组都是容器,它们的区别?
- 数组的长度是固定的,集合的长度是可变的
- 集合中存储的元素必须是引用类型数据
Arraylist集合继承关系
Arraylist继承了抽象类AbstractList,实现了接口List,List接口继承了Collection接口。
Collection 接口
|
----------------------------------------------------------------
| |
List接口 Set接口
| |
---------------- -------------
| | | |
ArrayList类 LinkedList类 HashSet类 LinkedHashSet类
LinkedList
特点
底层采用链表结构,每次查询都要从链头或者链尾找起,查询相对数组较慢,但是删除直接修改元素记录的地址即可不需要移动大量的元素
LinkedList的索引决定从链头开始找还是从链尾开始找,如果该元素小于元素长度的一半则从链头开始找起,如果大于元素长度的一半则从链尾找起
LinkedList特有方法
查询慢,增删快
- E removeFirst() 移除并返回链表的开头
- E removeLast() 移除并返回链表的结尾
- E getFirst() 获取链表的开头
- E getLast() 获取链表的结尾
- addFirst(E) 添加到链表的开头
- addLast(E) 添加到链表的结尾
Vector
Vector集合存储的结构时数组结构,为jdk中最早提供的集合,它是线程同步的,vector中提供了一个独特的取出方式,就是枚举Enumeration(它其实是早期的迭代器)。
Collection集合中的方法
- Object[] toArray() 集合中的元素转成一个数组中的元素,即集合转成数组。返回的是一个存储对象的数组,数组的存储对象数据类型是object Java中三种长度表现形式: 数组.length 属性——》返回值 int 字符串.length() 方法——》返回值 int 集合.size() 方法——》返回值 int
- boolean contains(Object o) 判断对象是否存在于集合中,对象存在则返回true
- void clear() 清空集合中的所有元素,但集合容器本身依然存在
- boolean remove(Object o) 移除集合中指定的元素
Collections
Collections与Collection采用了装饰模式,为Collection提供了更多的装饰方法
- Collections.shuffle方法 对List集合中的元素,进行随机排列
- Collections.binarySearch方法 对List集合进行二分搜索,方法参数(传递List集合,传递被查找的元素)
- Collections.sort方法 对于List集合,进行升序排列
迭代器
概述
Java中提供了很多集合,它们在存储元素时,采用的存储方式不同。我们取出这些集合中的元素,可以通过一种通用的方式来完成;
Collection集合元素的通用获取方式:在取元素之前先判断集合中是否有元素,如果有则把元素取出,循环执行,之至把集合中的所有元素全部取出。这种方式的专业术语成为迭代;
每种集合的底层的数据结构不同,例如ArrayList是数组、LinkedList是链表,但无论哪种集合都会使用迭代
迭代器的实现原理
接口Iterator有两个抽象方法
- next()取出集合的下一个元素
Collection接口中定义了方法 Iterator iterator(),ArrayList重写 Iterator iterator()方法,返回了Iterator接口的实现类对象。 Iterator it =array.iterator(),运行结果就是Iterator接口的实现类的对象,it是Iterator接口的实现类对象,调用方法 hasNext 和 next 集合元素迭代
……
//调用集合的方法iterator()获取出,Iterator接口的实现类的对象
Iterator<String> it = coll.iterator();
//接口实现类对象,调用方法hasNext()判断集合中是否有元素
//boolean b = it.hasNext();
//System.out.println(b);
//接口的实现类对象,调用方法next()取出集合中的元素
//String s = it.next();
//System.out.println(s);
//迭代是反复内容,使用循环实现,循环的条件,集合中没元素, hasNext()返回了false
while(it.hasNext()){
String s = it.next();
System.out.println(s);
}
……
迭代器的执行过程
private class Itr implements Iterator<E> {
int cursor; //下一个元素的索引值
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
// prevent creating a synthetic constructor
Itr() {}
//cursor记录的索引值不等于集合的长度返回true
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
集合迭代中的转型
- 在使用集合时需要注意:
- 集合中存储的其实都是对象的地址
- 集合中可以存储基本数值了(JDK1.5之后)。因为出席拿了基本类型的包装类,提供了自动装箱操作,这样集合中的元素就是基本数值的包装类对象。
- 存储时元素自动提升为Object,取出时要使用元素的特有内容,必须要向下转型。注意:如果集合中存放的是多个对象,这时向下转型会发生类型转换异常
- Iterator接口可以使用<>来控制迭代元素的类型,当使用Iterator
控制元素类型后,就不需要强转了。获取到的元素直接就是String类型
迭代器的并发修改异常
java.util.ConcurrentModificationException就是在遍历的过程中,使用了集合方法修改了集合的长度,不允许的
public class ListDemo1 {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("abc1");
list.add("abc2");
list.add("abc3");
list.add("abc4");
//对集合使用迭代器进行获取,获取时候判断集合中是否存在 "abc3"对象
//如果有,添加一个元素 "ABC3"
Iterator<String> it = list.iterator();
while(it.hasNext()){
String s = it.next();
//对获取出的元素s,进行判断,是不是有"abc3"
if(s.equals("abc3")){
list.add("ABC3");
}
System.out.println(s);
}
}
}
运行上述代码发生了错误 java.util.ConcurrentModificationException这是什么原因呢?
在迭代过程中,使用了集合的方法对元素进行操作。 导致迭代器并不知道集合中的变化,容易引发数据的不确定性。
并发修改异常解决办法: 在迭代时,不要使用集合的方法操作元素。 或者通过ListIterator迭代器操作元素是可以的,ListIterator的出现,解决了使用Iterator迭代过程中可能会发生的错误情况。
泛型
定义和使用
JDK1.5 出现新的安全机制,保证程序的安全性,泛型: 指明了集合中存储数据的类型 <数据类型>。
java中的伪泛型
泛型只在编译时存在,编译之后就被擦除了,在编译之前我们可以限制集合的类型,例如:
编译前:ArrayList
编译后:ArrayList al=new ArrayList();
泛型类
-
定义格式: 修饰符 class 类名<代表泛型的变量> { }
例如,API中的ArrayList集合: class ArrayList<E>{ public boolean add(E e){ } public E get(int index){ } } -
使用格式:创建对象时,确定泛型的类型
例如,ArrayList<String> list = new ArrayList<String>(); 此时,变量E的值就是String类型 class ArrayList<String>{ public boolean add(String e){ } public String get(int index){ } }
泛型的方法
-
定义格式:修饰符 <代表泛型的变量> 返回值类型 方法名(参数){ }
例如,API中的ArrayList集合中的方法: public <T> T[] toArray(T[] a){ } //该方法,用来把集合元素存储到指定数据类型的数组中,返回已存储集合元素的数组 -
使用格式:调用方法时,确定泛型的类型
例如: ArrayList<String> list = new ArrayList<String>(); String[] arr = new String[100]; String[] result = list.toArray(arr); 此时,变量T的值就是String类型。变量T,可以与定义集合的泛型不同 public <String> String[] toArray(String[] a){ }
泛型的好处
-
将运行时期的ClassCastException转移到了编译时期,变成了编译失败
-
避免了类型强转的麻烦
-
泛型的通配,匹配所有的数据类型 ? <?>
public static void main(String[] args) { //创建3个集合对象 ArrayList<ChuShi> cs = new ArrayList<ChuShi>(); ArrayList<FuWuYuan> fwy = new ArrayList<FuWuYuan>(); ArrayList<JingLi> jl = new ArrayList<JingLi>(); //每个集合存储自己的元素 cs.add(new ChuShi("张三", "后厨001")); cs.add(new ChuShi("李四", "后厨002")); fwy.add(new FuWuYuan("翠花", "服务部001")); fwy.add(new FuWuYuan("酸菜", "服务部002")); jl.add(new JingLi("小名", "董事会001", 123456789.32)); jl.add(new JingLi("小强", "董事会002", 123456789.33)); // ArrayList<String> arrayString = new ArrayList<String>(); iterator(jl); iterator(fwy); iterator(cs); } /* * 定义方法,可以同时遍历3集合,遍历三个集合的同时,可以调用工作方法 work * ? 通配符,迭代器it.next()方法取出来的是Object类型,怎么调用work方法 * 强制转换: it.next()=Object o ==> Employee * 方法参数: 控制,可以传递Employee对象,也可以传递Employee的子类的对象 * 泛型的限定 本案例,父类固定Employee,但是子类可以无限? * ? extends Employee 限制的是父类, 上限限定, 可以传递Employee,传递他的子类对象 * ? super Employee 限制的是子类, 下限限定, 可以传递Employee,传递他的父类对象 */public static void iterator(ArrayList<? extends Employee> array){Iterator<? extends Employee> it = array.iterator(); while(it.hasNext()){ //获取出的next() 数据类型,是什么Employee Employee e = it.next(); e.work(); } }
### List接口
#### 特点
1. 是一个元素存取有序的集合
2. 是一个带有索引的集合,通过索引就可以精确的操作集合中的元素(与数组的索引是一个道理)
3. 集合中可以有重复的元素,通过元素的equals方法,来比较是否为重复元素
4. 常用子接口
1. ArrayList集合
2. LinkedList集合
#### List接口特有的方法
- 增加元素方法
- add(Object e):向集合末尾处,添加指定的元素
- add(int index, Object e) 向集合指定索引处,添加指定的元素,原有元素依次后移**需要注意索引越界的问题**
- 删除元素方法
- remove(Object e):将指定元素对象,从集合中删除,返回值为被删除的元素
- remove(int index):将指定索引处的元素,从集合中删除,返回值为被删除的元素
- 替换元素方法
- set(int index, Object e):将指定索引处的元素,替换成指定的元素,返回值为替换前的元素
- 查询元素方法
- get(int index):获取指定索引处的元素,并返回该元素
### Set
#### 特点
- 不包含重复元素的集合,没有索引
- set集合取出元素的方式可以采用迭代器或者增强for循环
- set集合有多个子类,比如:HashSet、LinkedHashSet
### HashSet
- 底层数据结构——哈希表
- 存储、取出速度都比较快
- 线程不安全,运行速度快
### LinkedHashSet
- 基于链表的哈希表实现
- 继承HashSet
- 具有顺序,存储和取出的顺序相同
- 线程不安全的集合,运行速度快
### 哈希表
#### 哈希表的数据结构
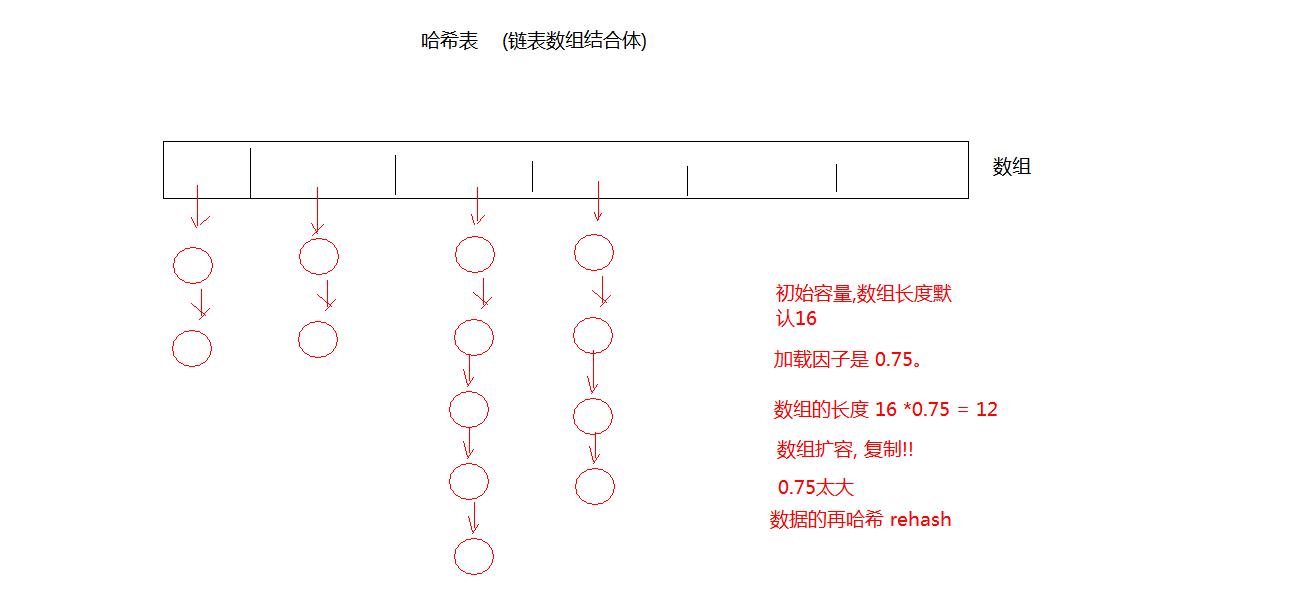
加载因子:表中填入的记录数/哈希表的长度。例如:加载因子是0.75 代表:数组中的16个位置,其中存入了12个元素。
如果在存入第十三个元素,导致存储链子过仓,会降低哈希表的性能,那么此时会扩充哈希表,底层会开辟一个长度为原长度**两倍**的数组,把老元素拷贝到新数组中,在把新元素添加到数组中
**当存入元素数量>哈希表长度*加载因子,就要扩容,因此加载因子决定扩容时机**
#### 字符串对象的哈希值
对象的哈希值,普通的十进制整数,父类Object的方法public int hashCode() 计算结果int整数
string类重写了hashCode方法
```java
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
hash = h = isLatin1() ? StringLatin1.hashCode(value)
: StringUTF16.hashCode(value);
}
return h;
}
哈希表的存储原理
每存入一个新的元素都要走一下三步:
- 首先调用本类的hashCod()方法算出哈希值
- 在容器中找是否有与新元素哈希值相同的老元素,如果没有直接存入,如果有跳转到第三步
- 新元素会与该索引下的老元素利用equals方法一一对比,一旦新元素.equals(老元素)返回true,停止对比,说明重复,不再存入。如果与该索引位置下的老元素对比后返回false,说明没有重复,存入
ArrayList,HashSet判断对象是否重复的原因
-
ArrayList的contains方法原理:底层依赖于equals方法。ArrayList调用contains方法会调用equals方法,传入的元素的equals方法依次与集合中的旧元素比较,从而根据返回的布尔值判断是否有重复的元素。此时,当ArrayList存放自定义的类型时,由于自定义类型在未重写equals方法前,判断是否重复的依据是地址值,所以如果想根据内容判断是否为重复元素,需要重写元素的equals方法
-
b:HashSet的add()方法和contains方法()底层都依赖 hashCode()方法与equals方法() Set集合不能存放重复的元素,其添加方法在添加时会判断是否有重复元素,有重复的不添加,没有重复的则添加。 HashSet集合由于时无序的,其判断唯一的依据是元素类型的hashCode与equals方法的返回结果,规则如下:
- 先判断新元素与集合内已经有的旧元素的HashCode值。
- 如果不同,说明是不同元素则添加到集合;
- 如果相同,在判断equals的比较结果,返回true则为相同元素,返回false则为不同元素添加到集合
所以,使用HashSet存储自定义类型,如果没有重写该类的hashcode与equals方法则判断重复时使用的是地址,如果想通过内容比较元素是否相同,需要重写该元素类的hashcode与equals方法。
hashCode和equals方法的面试题
- 两个对象 Person p1 p2 问题: 如果两个对象的哈希值相同 p1.hashCode()==p2.hashCode(),两个对象的equals一定返回true吗 ?p1.equals(p2) 一定是true吗? 正确答案:不一定。
- 如果两个对象的equals方法返回true,p1.equals(p2)==true,两个对象的哈希值一定相同吗? 正确答案:一定
解析:在Java应用程序执行期间,如果根据equals方法两个对象是相等的,那么对这两个对象中的每个对象的hash值都必须一样;如果根据equals方法,两个对象不相等,那么对这两个对象中的任意一个对象上调用hashCode方法不要求一定生成不同的整数结果。
两个对象不同(对象属性值不同) equals返回false=====>两个对象调用hashCode()方法哈希值相同
两个对象调用hashCode()方法哈希值不同=====>equals返回true
两个对象不同(对象属性值不同) equals返回false=====>两个对象调用hashCode()方法哈希值不同
两个对象调用hashCode()方法哈希值相同=====>equals返回true
所以说,两个对象的哈希值无论相同还是不同,equals都可能返回true
Map
概述
map接口下的集合与Collection接口下的集合,他们存储数据的形式不同
- Collection中的集合,元素是孤立存在的,像集合中存储元素采用一个个元素的方式存储
- map中的集合,元素是成对存在的。每个元素由键值两部分组成,通过键可以找到对应的值
- Collection中的集合称为单列集合,Map中的集合称为双列集合。
- 需要注意的是,Map中的集合不能包含重复的键,值可以重复;每个键只能对应一个值。
常用方法
-
V remove(K) 移除集合中的键值对,返回被移除之前的值
-
V get(K) 通过键对象,获取值对象
-
V put(K,V) K 作为键的对象, V作为值的对象。将键值对存储到集合中
- 存储的是重复的键,将原有的值,覆盖
- 返回值一般情况下返回null,
- 存储重复键的时候,返回被覆盖之前的值
-
遍历方法keySet方法
- 获取Map集合中所有的键,由于键是唯一的,所以返回一个Set集合存储所有的键
- 遍历键的Set集合,得到每一个键
- 根据键利用get(key)去Map找所对应的值
/* * Map集合的遍历 * 利用键获取值 * Map接口中定义方法keySet * 所有的键,存储到Set集合 */ public class MapDemo1 { public static void main(String[] args) { /* * 1. 调用map集合的方法keySet,所有的键存储到Set集合中 * 2. 遍历Set集合,获取出Set集合中的所有元素 (Map中的键) * 3. 调用map集合方法get,通过键获取到值 */ Map<String,Integer> map = new HashMap<String,Integer>(); map.put("a", 11); map.put("b", 12); map.put("c", 13); map.put("d", 14); //方法1 //1. 调用map集合的方法keySet,所有的键存储到Set集合中 Set<String> set = map.keySet(); //2. 遍历Set集合,获取出Set集合中的所有元素 (Map中的键) Iterator<String> it = set.iterator(); while(it.hasNext()){ //it.next返回是Set集合元素,也就是Map中的键 //3. 调用map集合方法get,通过键获取到值 String key = it.next(); Integer value = map.get(key); System.out.println(key+"...."+value); } //方法2 System.out.println("======================="); for(String key : map.keySet()){ Integer value = map.get(key); System.out.println(key+"...."+value); } } } -
Map集合Entry对象
- 在Map类设计时,提供了一个嵌套接口:Entry。
-
Entry将键值对的对应关系封装成了对象即键值对对象,这样我们在遍历Map集合时,就可以从每一个键值对(Entry)对象中获取对应的键与对应的值。
interface Map{
//Entry是Map的一个内部接口
//由Map的子类的内部类实现
interface Entry<K, V> {
K getKey();//获取Entry对象中的键
V getValue();//获取Entry对象中的值
V setValue(V value);
boolean equals(Object o);
int hashCode();
public static <K extends Comparable<? super K>, V> Comparator<Map.Entry<K, V>> comparingByKey() {
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getKey().compareTo(c2.getKey());
}
public static <K, V extends Comparable<? super V>> Comparator<Map.Entry<K, V>> comparingByValue() {
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getValue().compareTo(c2.getValue());
}
public static <K, V> Comparator<Map.Entry<K, V>> comparingByKey(Comparator<? super K> cmp) {
Objects.requireNonNull(cmp);
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> cmp.compare(c1.getKey(), c2.getKey());
}
public static <K, V> Comparator<Map.Entry<K, V>> comparingByValue(Comparator<? super V> cmp) {
Objects.requireNonNull(cmp);
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> cmp.compare(c1.getValue(), c2.getValue());
}
}
}
-
Map集合遍历方式entrySet方法 Map集合获取方式,entrySet方法,键值对映射关系(结婚证)获取 实现步骤:
-
- 调用map集合方法entrySet()将集合中的映射关系对象,存储到Set集合Set<Entry <K,V> >
- 迭代Set集合
- 获取出的Set集合的元素,是映射关系对象
- 通过映射关系对象方法 getKet, getValue获取键值对
创建内部类对象 外部类.内部类 = new
public static void main(String[] args) { Map<Integer,String> map = new HashMap<Integer, String>(); map.put(1, "abc"); map.put(2, "bcd"); map.put(3, "cde"); //1. 调用map集合方法entrySet()将集合中的映射关系对象,存储到Set集合 Set<Map.Entry <Integer,String> > set = map.entrySet(); //2. 迭代Set集合 Iterator<Map.Entry <Integer,String> > it = set.iterator(); while(it.hasNext()){ // 3. 获取出的Set集合的元素,是映射关系对象 // it.next 获取的是什么对象,也是Map.Entry对象 Map.Entry<Integer, String> entry = it.next(); //4. 通过映射关系对象方法 getKet, getValue获取键值对 Integer key = entry.getKey(); String value = entry.getValue(); System.out.println(key+"...."+value); } } }
HashMap
LinkedHashMap
特点:保证迭代顺序
HashTable
特点
- 底层数据结构为哈希表,特点和hashmap一样
- Hashtable是线程安全的集合,运行速度慢
- Hashtable命运和Vector是一样的,从JDK1.2开始,被更先进的HashMap取代
- Hashtable 不允许存储null值,null键;HashMap 允许存储null值,null键