
Single Node Setup
1. 本地模式
2.伪分布式模式
********* 本地模式 **********

- . grep input output ‘dfs[a-z.]+’ 运行mapreduce的例子,input是当前目录下的文件夹;output是运行输出结果储存的地方,并且在当前目录下没有。’dfs[a-z.]+’是检索的参数
可以看到运行成功后,目录中出现了output。output中有_success文件说明成功。运算结果在part-r-00000中,结果如图2-2所示。
- bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount wcinput wcoutput
查看wcinput中wc.input文件中单词的数量,运行结果如下:*** ********* 伪分布式**********
- hadoop的端口号一般为8020
- namenode存储的元数据
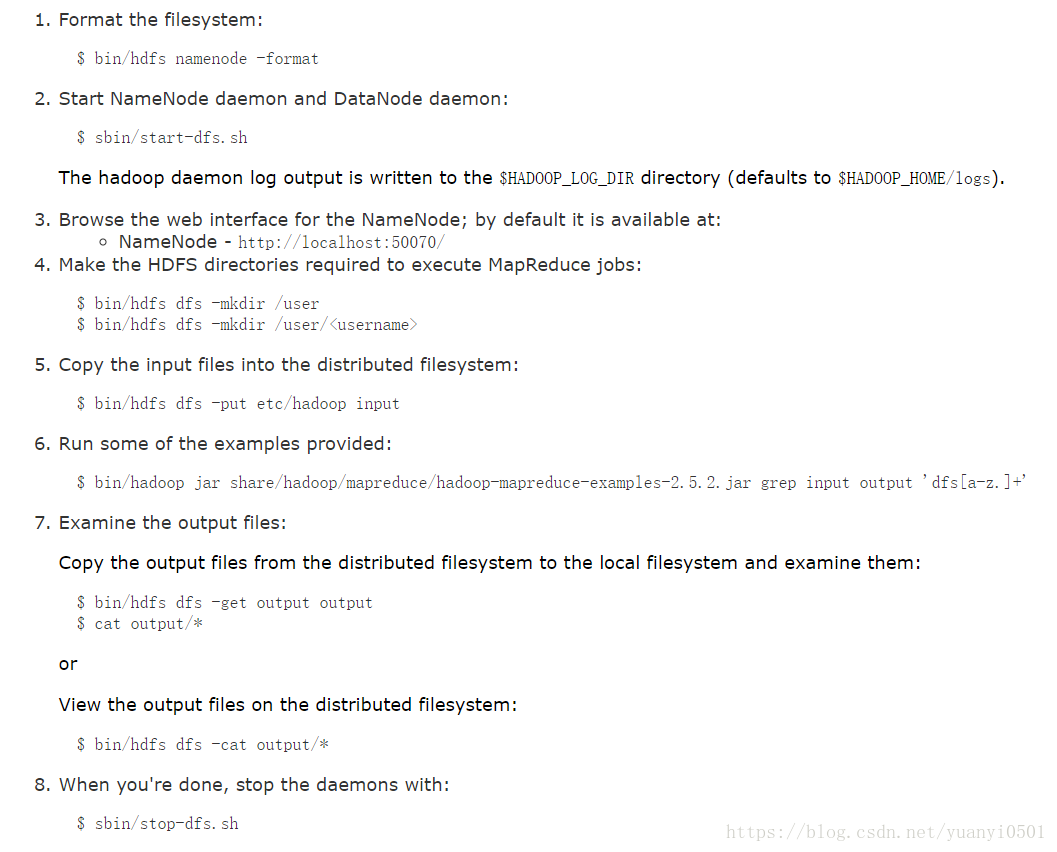
- $ bin/hdfs namenode -format namenode格式化
- sbin/hadoop-daemon.sh start namenode 启动namenode
- sbin/hadoop-daemon.sh start datanode 启动datanode。
- 在根目录下会出现log文件夹,说明启动成功
- 访问192.168.220.128:50070
- 具体步骤:
-
- 具体步骤:
-
YARN on Single Node
- 步骤如下:
*******
启动方式
- 服务逐一启动 hdfs:sbin/hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode yarn:sbin/yarn-daemon.sh start|stop resourcemanager|nodemanager mapreduce: sbin/mr-historyserver-daemon.sh start|stop history
- 各个模块启动:(配置ssh无密钥登陆) hdfs:sbin/start-dfs.sh yarn:sbin/start-yarn.sh
- 一起启动:
sbin/start-all.sh
配置文件
HDFS
- NameNode:core-site.xml文件
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>———》指定了namenode运行的机器hostname:8020
</property>
-
DataNode:slaves文件
-
SecondaryNamenode:hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>"hostname":50090</value>————》指定了namenode运行的机器
</property>
YARN
- ResourceManager:yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hsotname</value>
</property>
-
NodeManager:slaves文件
- MapReduce:mapred-site.xml
- HistoryServer:mapred-site.xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>hsotname:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hsotname:19888</value>
</property>